やましいことがあまりないのなら、身元がわかる程度のことはしておいてほしいかなぁと思う。
ec2-52-197-160-182.ap-northeast-1.compute.amazonaws.com
544PV
ec2-52-197-160-211.ap-northeast-1.compute.amazonaws.com
540PV
・計1084PV
・2秒おきに1アクセス
・すべて別記事なので、1084記事クロールされていた
それも夕方の18時19時にアクセスがあった。
なんとなく気持ち悪いので、アクセスログみたらUAにちゃんと身元?らしきものが書かれていた
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.90 Safari/537.36 (compatible; SBooksNet/1.0; +http://s-books.net/crawl_policy)
UAにかかれているURLアクセスしてみると以下の通り
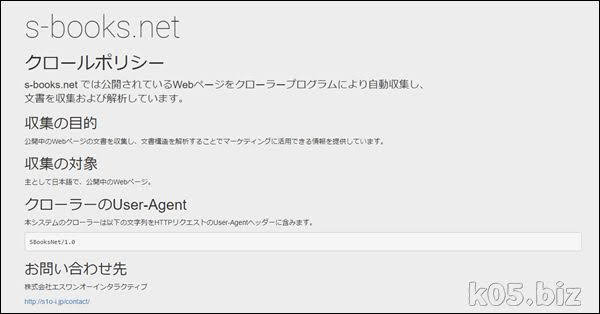
s-books.net
クロールポリシー
s-books.net では公開されているWebページをクローラープログラムにより自動収集し、
文書を収集および解析しています。
収集の目的
公開中のWebページの文書を収集し、文書構造を解析することでマーケティングに活用できる情報を提供しています。
収集の対象
主として日本語で、公開中のWebページ。
クローラーのUser-Agent
本システムのクローラーは以下の文字列をHTTPリクエストのUser-Agentヘッダーに含みます。
SBooksNet/1.0
http://s-books.net/crawl_policy
これを見る限りでは、いやならUAで拒否してくれという感じだと思う。
たぶん、robots.txtで拒否したら、遠慮するんじゃないかなぁ。
身元らしきものはわかったんだけど、目的が分からないんですね。
記事のコピーでなくて、何らかのSEO的な?調査のような気がします。
・アドセンスのPVは増えてなかった
・Google AnalyticsのPVは増えていた
ということなので、実際にHTMLを取得するだけでなくて、レンダリング(表示)もしてると思う。ただし、アドセンスとかは表示しないようにしてるとかそういう感じではないかなぁと思う。
時々あるパターン
・compute.amazonaws.comあたりからのアクセス・深夜0時から3時ぐらい
・2秒間に1PV
・すべて別記事で、500程度から1000記事程度クロール
なぜか2秒毎というのが多い気がする。
安い共有サーバーを使ってる場合は、基本、どの時間帯もこの手のアクセスは迷惑だとは思う。深夜にしてるのは負荷がかかりにくいからだとは思うんだけどね。
深夜にアクセス多いというよりかは、たぶん、バックアップとかそういうのをみんな動かしてるんじゃないかなぁと思う。
私の使っているレンタルサーバーは、比較的早朝とかは、体感では軽い気がするけど・・。バックアップとかもAM4:00とか早朝に設定したほうが良いかも。
私は早朝に設定してるけど、たまに早朝にメンテナンスが入るので、そういうのがあるとその時だけバックアップが動かないけどね。
補足:amazonaws.com
今すぐ AWS で構築を始めましょう
コンピューティング、データベースストレージ、コンテンツ配信や他の機能が必要な際も、AWS は柔軟性、スケーラビリティー、信頼性の高い洗練されたアプリケーション構築を実現するサービスを提供します。
クラウドならアマゾン ウェブ サービス 【AWS 公式】
たぶん、Amazonがやっているレンタルサーバー(ホスティングサービス)からアクセスすると、今回のログを残すみたい。
同じことを安いレンタルサーバーでやったら、追い出されるかもしれないので、この手のAESとかGoogle App Engine (GAE) ?とか使うんじゃないかなぁと素人目には思います。
AESとかは、転送量で金かかる(はず)。
結局、何が目的なのか?!
今回の件関係なく、この手のアクセスは何が目的なのか?っていう話。・SEO的な何かを調べてる
・記事をパクるためとかではなさそうな雰囲気
・登録しているアフィリエイト関連の調査
・記事依頼するための事前調査
・アフィリエイトでおすすめのキーワードを抽出するため
結局、わかりませんが、推測だけ。
なにか対策するべきなのか?!
僕は特に対策してません。スポンサーリンク